BigDL-LLM
格局小了! LLM 功能只是 BigDL 的一部分,原以为只是关于大语言模型的。英特尔出品
说是针对大语言模型的优化加速库,也确实是如此,有点类似
这次的测试环境还是我的老朋友,和初次体验
项目介绍
为了测试上述功能,新建了一个项目。根据不同的功能做一个分类:01_history_chat 、02_knowledge_chat 、 03_api 、 config 等。
config 目录
这里存放一些配置文件或者公共变量等
model.py
模型相关的配置放到这里,例如:本地模型的路径
model_path_dict = {
"baichuan" : {
"2-7B-Chat" : "D:\\llm\\baichuan-inc\\Baichuan2-7B-Chat",
},
"THUDM" : {
"2-6b" : "D:\llm\THUDM\chatglm2-6b",
"3-6b" : "D:\llm\THUDM\chatglm3-6b"
},
"Qwen" : {
"7B-Chat" : "D:\llm\Qwen\Qwen-7B-Chat"
},
"01ai" : {
"6B-Chat" : "D:\\llm\\01ai\\Yi-6B-Chat"
}
}
question.py
准备了一些测试问题,放在了该文件中
history_chat_questions = ["你好", "中国的首都是", "他的面积是多少", "他有几座机场", "一共问了你几个问题"]
虚拟环境
# 创建、激活虚拟环境
python -m venv venv
.\venv\scripts\activate
# 【linux】创建、激活虚拟环境
python3 -m venv venv
source ./venv/bin/activate
# 退出虚拟环境
deactivate
pip install --pre --upgrade bigdl-llm[all]
# 【linux】安装CPU版本的 torch
# 说明:如果需要 linux 下 CPU 版本的 torch ,请先安装 torch 之后再安装 bigdl-llm
# !!!测试发现先安装 bigdl-llm 之后再安装 CPU 版本的 torch 没有成功
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
bigdl-llm[all] 包依赖 transformers , 安装时会自动将其带上
2024-02-26 bigdl-llm[all]的版本是:2.5.0b20240225 ,对应的 transformers 版本是:4.31.0
2024-02-27 bigdl-llm[all]的版本是:2.5.0b20240226 ,对应的 transformers 版本是:4.31.0
历史对话
Baichuan2-7B-Chat
点击查看代码
# 引用本地依赖需要,例如:引用 config.model
import sys
sys.path.append(".")
from transformers import AutoTokenizer
from bigdl.llm.transformers import AutoModelForCausalLM
from config.model import model_path_dict
from config.question import history_chat_questions
model_path = model_path_dict["baichuan"]["2-7B-Chat"]
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, load_in_4bit=True, trust_remote_code=True, use_cache=True)
# model.chat 方法位于模型权重文件夹的 modeling_baichuan.py 文件中,如下:
'''
def chat(self, tokenizer, messages: List[dict], stream=False, generation_config: Optional[GenerationConfig]=None)
'''
# 该方法没有 temperature 、 top_p 等参数, generation_config 参数这里没有传入。默认采用的是 generation_config.json 文件中的配置
# 你可以这样获取模型权重的 GenerationConfig
'''
from transformers.generation.utils import GenerationConfig
generation_config = GenerationConfig.from_pretrained(model_path)
print(str(generation_config))
'''
messages=[]
for question in history_chat_questions:
print("问:" + question)
messages.append({"role": "user", "content": question})
response = model.chat(tokenizer, messages)
messages.append({"role": "assistant", "content": response})
print("答:" + str(response))
print(str(messages))
这个比较顺利,仅安装
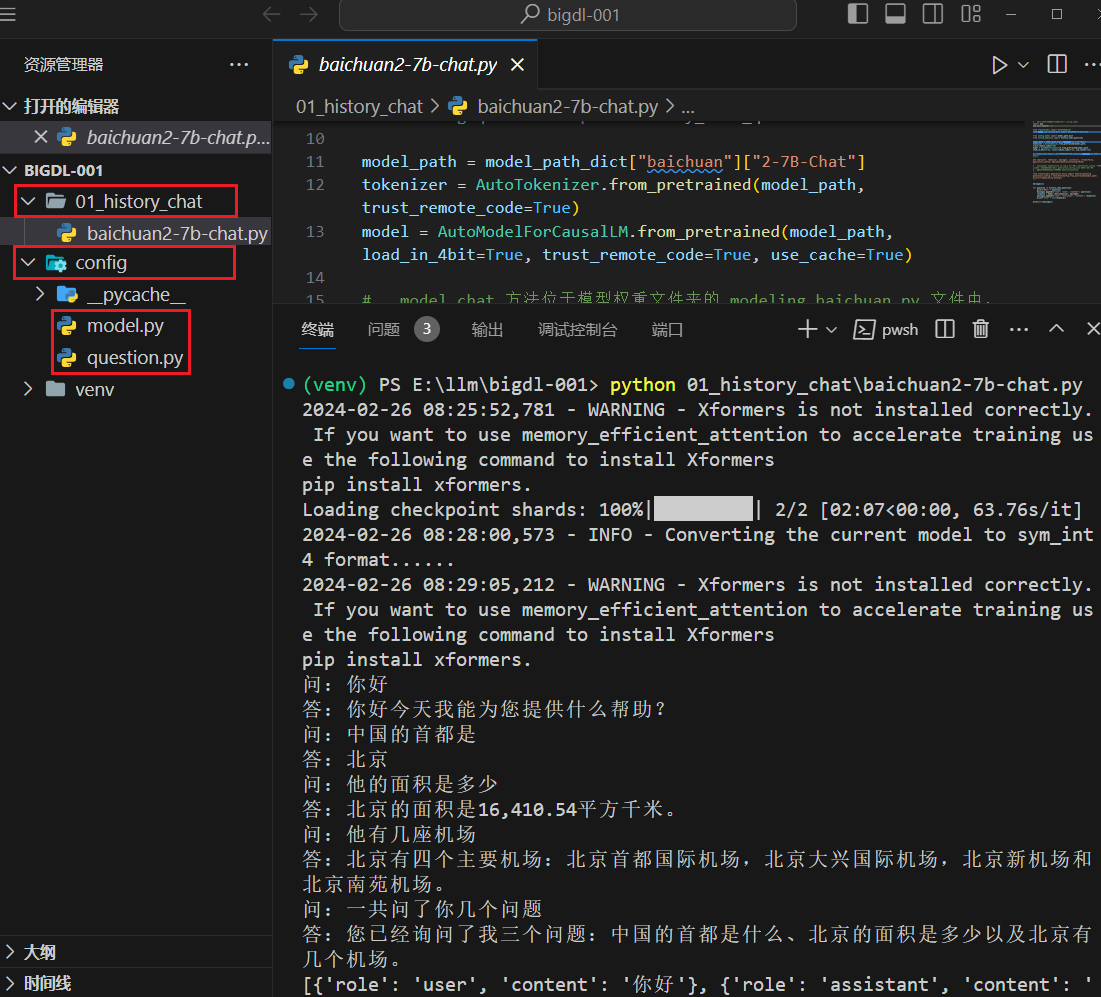
执行时会有如下的警告
WARNING - Xformers is not installed correctly. If you want to use memory_efficient_attention to accelerate training use the following command to install Xformers
pip install xformers.
chatglm2-6b
点击查看代码
import sys
sys.path.append(".")
from transformers import AutoTokenizer
from bigdl.llm.transformers import AutoModel
from config.model import model_path_dict
from config.question import history_chat_questions
model_path = model_path_dict["THUDM"]["2-6b"]
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, load_in_4bit=True, trust_remote_code=True)
# model.chat 方法位于模型权重文件夹的 modeling_chatglm.py 文件中,如下:
'''
def chat(self, tokenizer, query: str, history: List[Tuple[str, str]] = None, max_length: int = 8192, num_beams=1,do_sample=True, top_p=0.8, temperature=0.8, logits_processor=None, **kwargs)
'''
messages = []
history = None
for question in history_chat_questions:
print("问:" + question)
response, history = model.chat(tokenizer, question, history=history)
print("答:" + str(response))
for question, response in history:
messages.append({"role": "user", "content": question})
messages.append({"role": "assistant", "content": response})
print(str(messages))
chatglm2-6b 模型官方建议依赖的 transformers 版本为:4.30.2 。transformers 4.31.0,这个版本也可以,下面看一下运行效果:
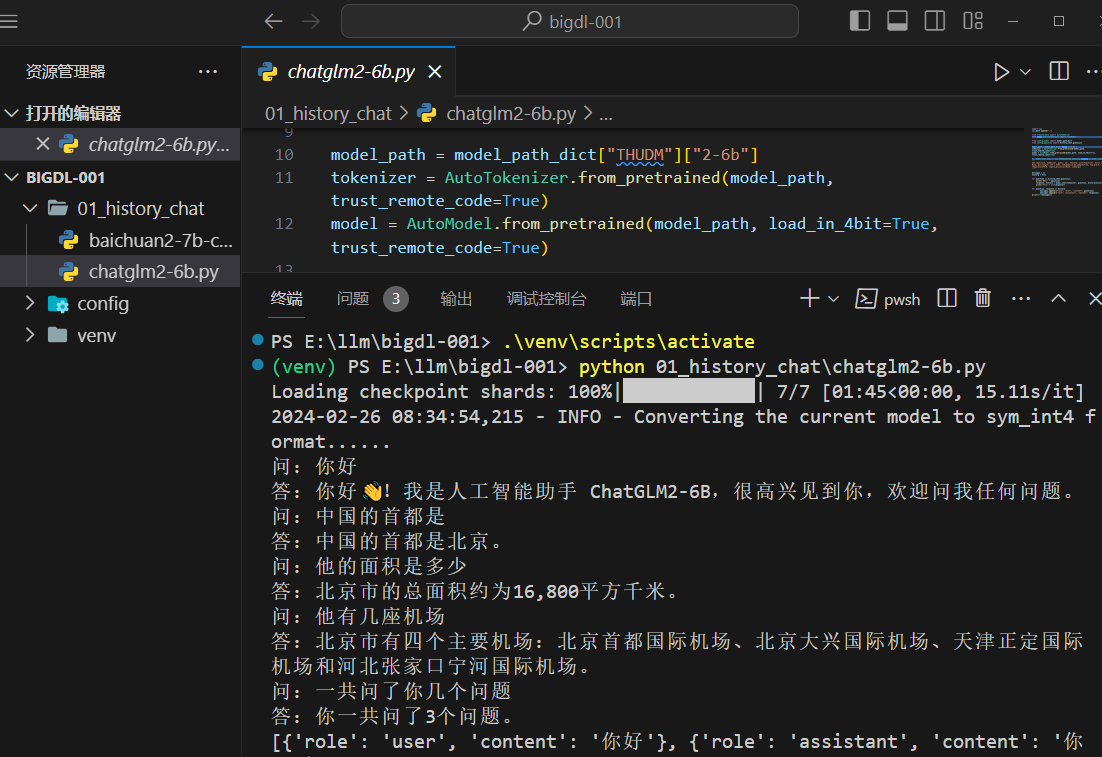
chatglm3-6b
点击查看代码
import sys
sys.path.append(".")
from transformers import AutoTokenizer
from bigdl.llm.transformers import AutoModel
from config.model import model_path_dict
from config.question import history_chat_questions
model_path = model_path_dict["THUDM"]["3-6b"]
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, load_in_4bit=True, trust_remote_code=True)
# model.chat 方法位于模型权重文件夹的 modeling_chatglm.py 文件中,如下:
'''
def chat(self, tokenizer, query: str, history: List[Tuple[str, str]] = None, role: str = "user", max_length: int = 8192, num_beams=1, do_sample=True, top_p=0.8, temperature=0.8, logits_processor=None, **kwargs)
'''
# 【说明】感觉形参 history 的数据类型写错了,该方法内部会调用 tokenization_chatglm.py 文件中的 build_chat_input 方法(类型明显不一致)
history = None
for question in history_chat_questions:
print("问:" + question)
response, history = model.chat(tokenizer, question, history=history)
print("答:" + str(response))
print(str(history))
chatglm3-6b 也是如此,仅安装
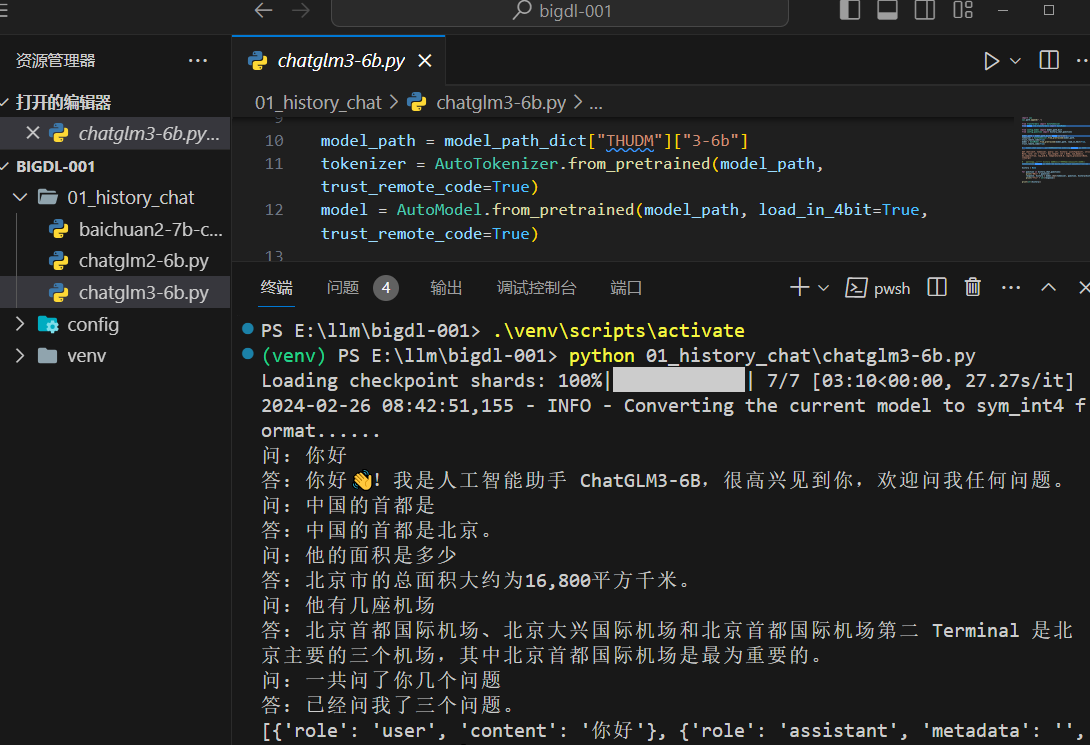
Qwen-7B-Chat
点击查看代码
import sys
sys.path.append(".")
from transformers import AutoTokenizer
from bigdl.llm.transformers import AutoModelForCausalLM
from config.model import model_path_dict
from config.question import history_chat_questions
model_path = model_path_dict["Qwen"]["7B-Chat"]
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, load_in_4bit=True, trust_remote_code=True)
# model.chat 方法位于模型权重文件夹的 modeling_qwen.py 文件中,如下:
'''
def chat(self,tokenizer: PreTrainedTokenizer,query: str,history: Optional[HistoryType],system: str = "You are a helpful assistant.",append_history: bool = True,stream: Optional[bool] = _SENTINEL,stop_words_ids: Optional[List[List[int]]] = None,generation_config: Optional[GenerationConfig] = None,**kwargs,) -> Tuple[str, HistoryType]
'''
messages=[]
history = None
for question in history_chat_questions:
print("问:" + question)
response, history = model.chat(tokenizer, question, history=history)
print("答:" + str(response))
for question, response in history:
messages.append({"role": "user", "content": question})
messages.append({"role": "assistant", "content": response})
print(str(messages))
Qwen-7B-Chat 也还可以,除了已安装的
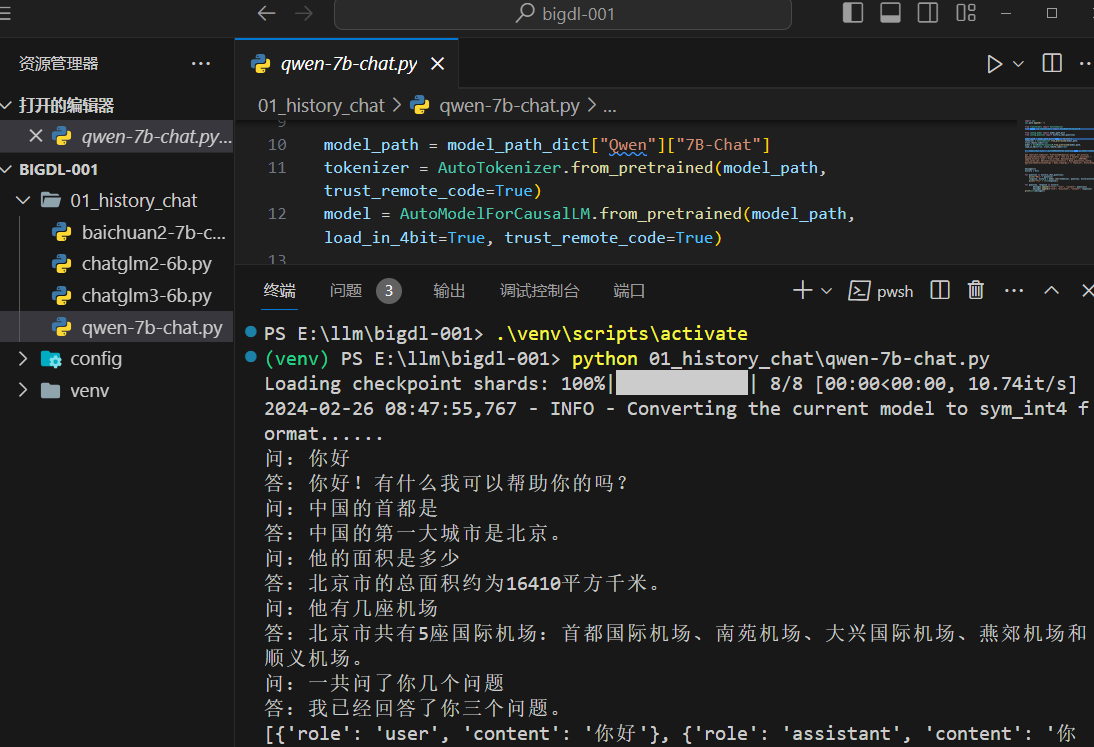
Yi-6B-Chat
比较爽的是,发现了下面这些站点,遗憾的是没有找到支持的其他模型。
点击查看代码
import sys
sys.path.append(".")
from typing import Optional, Tuple, List
import copy
from transformers import AutoTokenizer
from bigdl.llm.transformers import AutoModelForCausalLM
from config.model import model_path_dict
from config.question import history_chat_questions
model_path = model_path_dict["01ai"]["6B-Chat"]
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, load_in_4bit=True, trust_remote_code=True)
# 这个模型比较费劲啊,没有 model.chat 方法,下面是自己封装的一些方法
def chat1(
model,
tokenizer,
query: str,
history: Optional[List[Tuple[str, str]]],
system: str = "You are a helpful assistant.",
**kwargs,
) -> Tuple[str, List[Tuple[str, str]]]:
im_start, im_end = "<|im_start|>", "<|im_end|>"
# tokenizer.encode("<|im_start|>", return_tensors="pt") => 6
# tokenizer.encode("<|im_end|>", return_tensors="pt") => 7
if history is None:
history = []
else:
# make a copy of the user's input such that is is left untouched
history = copy.deepcopy(history)
raw_text = f"\n{im_start}system\n{system}{im_end}\n"
for turn_query, turn_response in history:
raw_text += f"{im_start}user\n{turn_query}{im_end}\n"
raw_text += f"{im_start}assistant\n{turn_response}{im_end}\n"
raw_text += f"{im_start}user\n{query}{im_end}\n"
raw_text += f"{im_start}assistant\n"
input_ids = tokenizer.encode(raw_text, return_tensors="pt")
outputs = model.generate(input_ids,
do_sample=True,
max_new_tokens=4096,
top_p=0.8,
temperature=0.8)
response = tokenizer.decode(outputs[0][len(input_ids[0]):], skip_special_tokens=True)
history.append((query, response))
return response, history
def chat2(model, tokenizer, messages, system: str = "You are a helpful assistant."):
im_start, im_end = "<|im_start|>", "<|im_end|>"
prompt = f"\n{im_start}system\n{system}{im_end}\n"
for message in messages:
match message["role"]:
case "user":
prompt += f"{im_start}user\n{message['content']}{im_end}\n"
case "assistant":
prompt += f"{im_start}assistant\n{message['content']}{im_end}\n"
prompt += f"{im_start}assistant\n"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
outputs = model.generate(input_ids,
do_sample=True,
max_new_tokens=4096,
top_p=0.8,
temperature=0.8)
response = tokenizer.decode(outputs[0][len(input_ids[0]):], skip_special_tokens=True)
return response
def chat3(model,tokenizer,messages):
# apply_chat_template 方法需要安装较新版本的 transformers
input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt')
output_ids = model.generate(input_ids)
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
return response
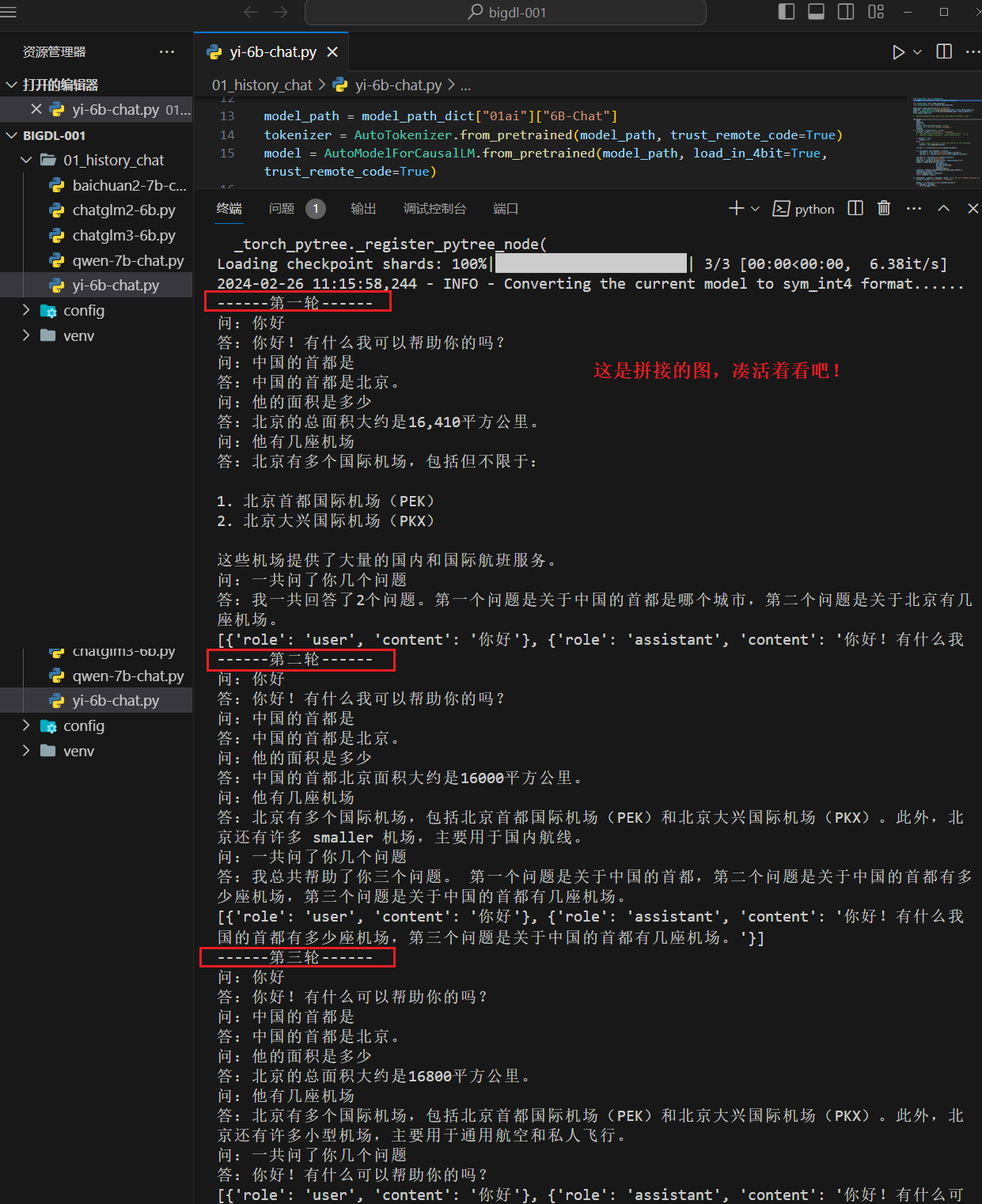
print("------第一轮------")
messages1=[]
history = None
for question in history_chat_questions:
print("问:" + question)
response, history = chat1(model, tokenizer, question, history=history)
print("答:" + str(response))
for question, response in history:
messages1.append({"role": "user", "content": question})
messages1.append({"role": "assistant", "content": response})
print(str(messages1))
print("------第二轮------")
messages2=[]
for question in history_chat_questions:
print("问:" + question)
messages2.append({"role": "user", "content": question})
response = chat2(model, tokenizer, messages2)
messages2.append({"role": "assistant", "content": response})
print("答:" + str(response))
print(str(messages2))
print("------第三轮------")
messages3=[]
for question in history_chat_questions:
print("问:" + question)
messages3.append({"role": "user", "content": question})
response = chat3(model,tokenizer, messages3)
messages3.append({"role": "assistant", "content": response})
print("答:" + str(response))
print(str(messages3))
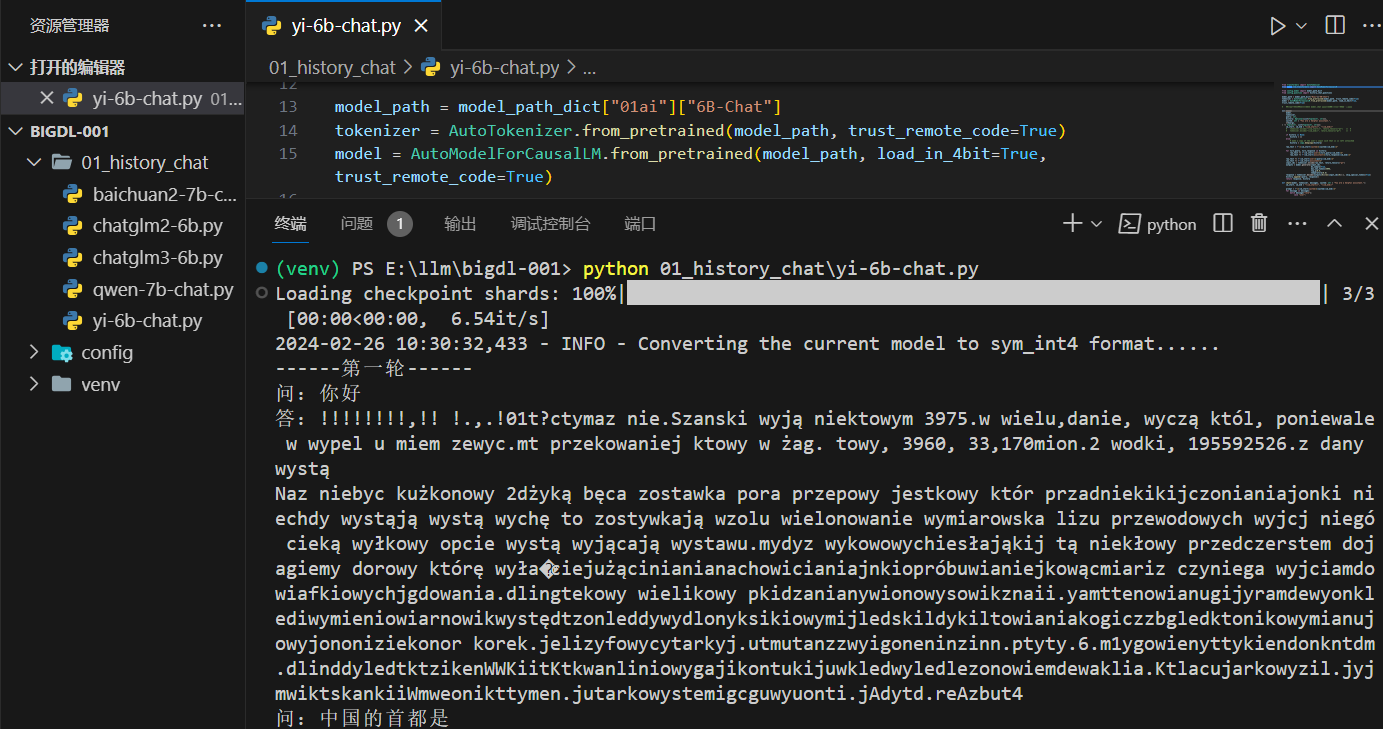
Yi-6B-Chat 这个就比较费劲儿了,没有类似上面的
点击查看 transformers 版本尝试
- bigdl-llm[all]:2.5.0b20240225 ,transformers:4.31.0
-
------第一轮------ 问:你好 答:你好!有什么我可以帮助你的吗? 问:中国的首都是 答:中国的首都是北京。 问:他的面积是多少 答:他的面积是多少?这个问题需要更多的信息才能给出一个准确的答案。如果你能 提供更多的关于他的信息,比如他的名字,出生日期,住址等等,那么我就可以根据 你所提供的这些信息来帮助你回答这个问题:他的面积是多少? 问:他有几座机场 答:他有几座机场?这个问题需要更多的信息才能给出一个准确的答案。如果你能提 供更多的关于他的信息,比如他的名字,出生日期,住址等等,那么我就可以根据你 所提供的这些信息来帮助你回答这个问题:他有几座机场? 问:一共问了你几个问题 答:一共问了你几个问题?这个问题需要更多的信息才能给出一个准确的答案。如果 你能提供更多的关于你的信息,比如你的名字,出生日期,住址等等,那么我就可以 根据你所提供的这些信息来帮助你回答这个问题:一共问了你几个问题?? ------第二轮------ 问:你好 答:你好!有什么我可以帮助你的吗? 问:中国的首都是 答:中国的首都是北京。 问:他的面积是多少 答:他的面积是多少?看起来你可能是在询问某人的面积。但是,由于缺乏上下文, 我无法提供你询问的面积。如果你能提供更多的上下文,我将很乐意帮助你找到你询 问的面积。 问:他有几座机场 答:他有几座机场?看起来你可能是在询问某人的机场数量。但是,由于缺乏上下文 ,我无法提供你询问的机场数量。如果你能提供更多的上下文,我将很乐意帮助你找 到你询问的机场数量。 问:一共问了你几个问题 答:一共问了你几个问题?看起来你可能是在询问你总共被问了几个问题。但是,由 于缺乏上下文,我无法提供你询问的上下文。如果你能提供更多的上下文,我将很乐 意帮助你找到你询问的上下文。 ------第三轮------ 问:你好 Traceback (most recent call last): File "E:\llm\bigdl-001\01_history_chat\yi-6b-chat.py", line 109, in <module> response = chat3(model,tokenizer, messages3) File "E:\llm\bigdl-001\01_history_chat\yi-6b-chat.py", line 77, in chat3 input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt') AttributeError: 'LlamaTokenizerFast' object has no attribute 'apply_chat_template'说明:在这个版本下没有根据上下文(对话历史)回答问题,并且第三轮还报错了,第三轮需要更高版本的 transformers 来支持 apply_chat_template 方法
- bigdl-llm[all]:2.5.0b20240225 ,transformers:4.38.1
-
这个版本会报如下错误(去掉了一些堆栈信息)
TypeError: LlamaRotaryEmbedding.forward() missing 1 required positional argument: 'position_ids'
- bigdl-llm[all]:2.5.0b20240225 ,transformers:4.37.0 或者 4.36.0
-
-
之前测试的时候(2024-02-19) 安装 transformers==4.37.2 配合 bigdl 测试时会有如下错误,这次没有验证,如下:
KeyError: 'Cache only has 0 layers, attempted to access layer with index 0'
在
知识库问答
这里的测试是在
项目调整
新增目录
1、
# 参考 Langchain-Chatchat 项目的写法
# 会在知识库问答中使用
knowledge_chat_prompt_template="""<指令>根据已知信息,简洁和专业的来回答问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题”,不允许在答案中添加编造成分,答案请使用中文。 </指令>
<已知信息>{knowledge}</已知信息>
<问题>{question}</问题>"""
2、
from .prompt_template import knowledge_chat_prompt_template
history_chat_questions = ["你好", "中国的首都是", "他的面积是多少", "他有几座机场", "一共问了你几个问题"]
knowledge_chat_questions = [
"你好",
"中国的首都是",
"他的面积是多少",
"他有几座机场",
"你知道 xiaodu114 吗?",
knowledge_chat_prompt_template.format(knowledge='''一个关于xiaodu114的秘密
xiaodu114很喜欢球类运动,例如:乒乓球、羽毛球、网球等。
xiaodu114热爱学习,并且非常喜欢编程,🤭🤭🤭
你知道吗?xiaodu114还是Reddit的注册用户哦!访问地址为:https://www.reddit.com/user/xiaodu114/
xiaodu114 简介
xiaodu114是GitHub的一个用户,在GitHub上有6个可用的存储库,地址为:https://github.com/xiaodu114 。
xiaodu114同时也是npmjs的注册用户,目前已经创建了两个库:a2bei4 和 a2bei4-rollup-plugin 。''', question="介绍一下 xiaodu114")]
Baichuan2-7B-Chat
点击查看代码
import sys
sys.path.append(".")
from transformers import AutoTokenizer
from bigdl.llm.transformers import AutoModelForCausalLM
from config.model import model_path_dict
from config.question import knowledge_chat_questions
model_path = model_path_dict["baichuan"]["2-7B-Chat"]
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, load_in_4bit=True, trust_remote_code=True, use_cache=True)
def chat(model,tokenizer,messages:list[dict]):
prompt = ""
for message in messages:
match message["role"]:
case "user":
prompt += "<reserved_106>" + message["content"] + "\n"
case "assistant":
prompt += "<reserved_107>" + message["content"] + "\n"
prompt += "<reserved_107>"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
output_ids = model.generate(input_ids,
do_sample=True,
max_new_tokens=4096,
top_p=0.8,
temperature=0.8)
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
return response
messages=[]
for question in knowledge_chat_questions:
print("问:" + question)
messages.append({"role": "user", "content": question})
response = chat(model, tokenizer, messages)
messages.append({"role": "assistant", "content": response})
print("答:" + str(response))
print(str(messages))
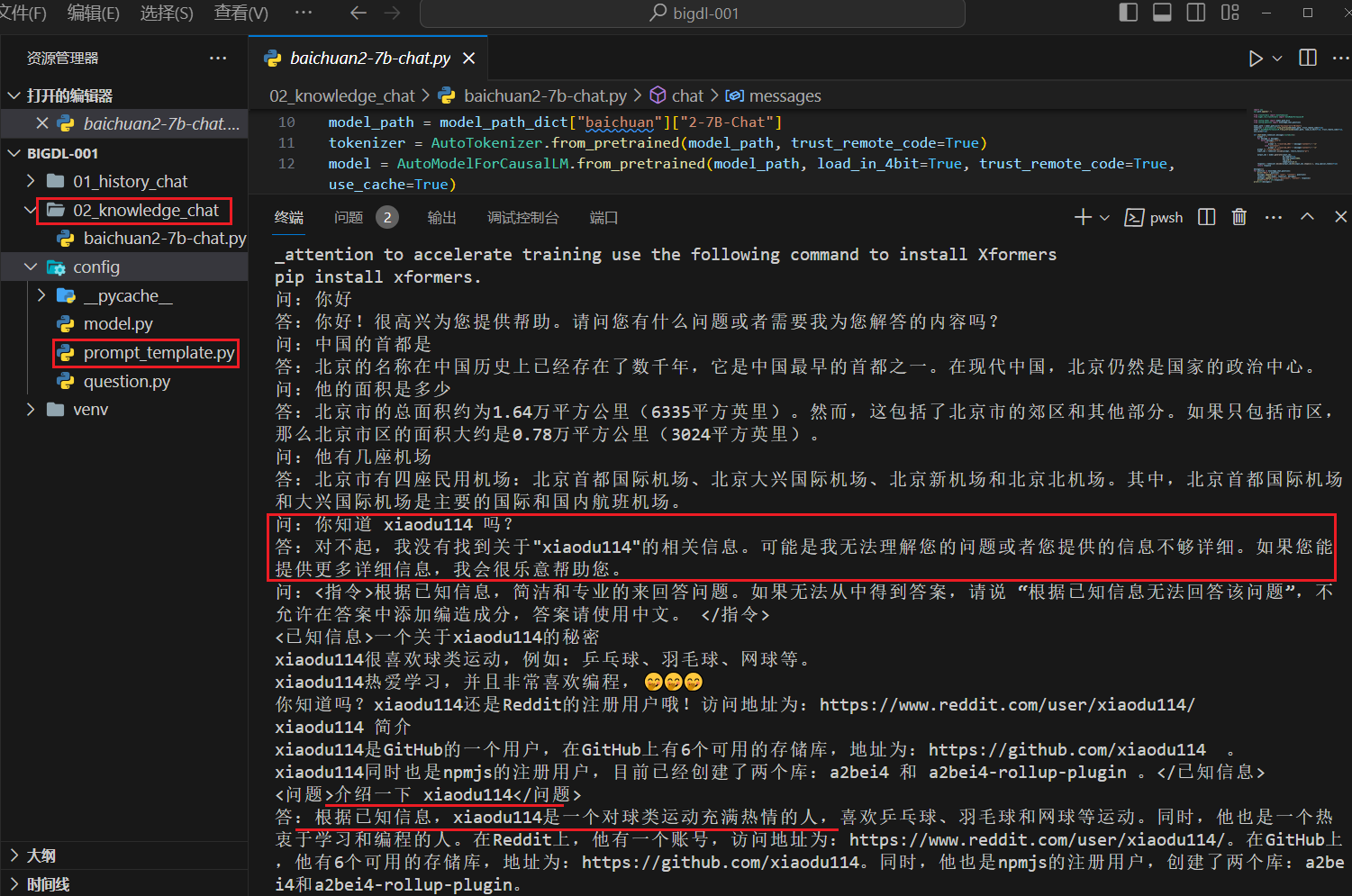
安装的依赖包和上面对应的历史对话章节相同。下面看一下运行效果:
chatglm2-6b
点击查看代码
import sys
sys.path.append(".")
from transformers import AutoTokenizer
from bigdl.llm.transformers import AutoModel
from config.model import model_path_dict
from config.question import knowledge_chat_questions
model_path = model_path_dict["THUDM"]["2-6b"]
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, load_in_4bit=True, trust_remote_code=True)
messages=[]
history = None
for question in knowledge_chat_questions:
print("问:" + question)
response, history = model.chat(tokenizer, question, history=history)
print("答:" + str(response))
for question, response in history:
messages.append({"role": "user", "content": question})
messages.append({"role": "assistant", "content": response})
print(str(messages))
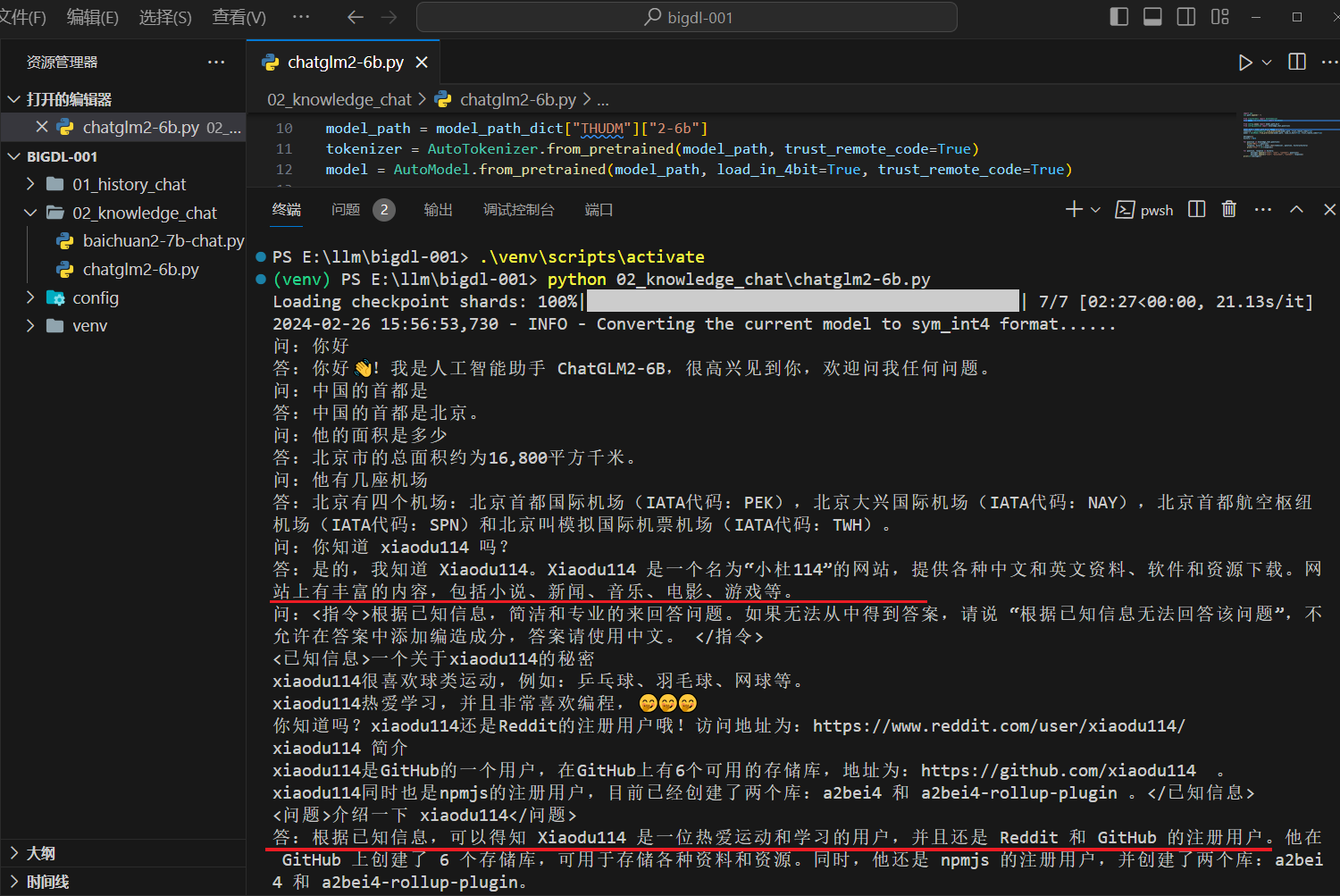
安装的依赖包和上面对应的历史对话章节相同。下面看一下运行效果:
chatglm3-6b
点击查看代码
import sys
sys.path.append(".")
from transformers import AutoTokenizer
from bigdl.llm.transformers import AutoModel
from config.model import model_path_dict
from config.question import knowledge_chat_questions
model_path = model_path_dict["THUDM"]["3-6b"]
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, load_in_4bit=True, trust_remote_code=True)
history = None
for question in knowledge_chat_questions:
print("问:" + question)
response, history = model.chat(tokenizer, question, history=history)
print("答:" + str(response))
print(str(history))
安装的依赖包和上面对应的历史对话章节相同。下面看一下运行效果:
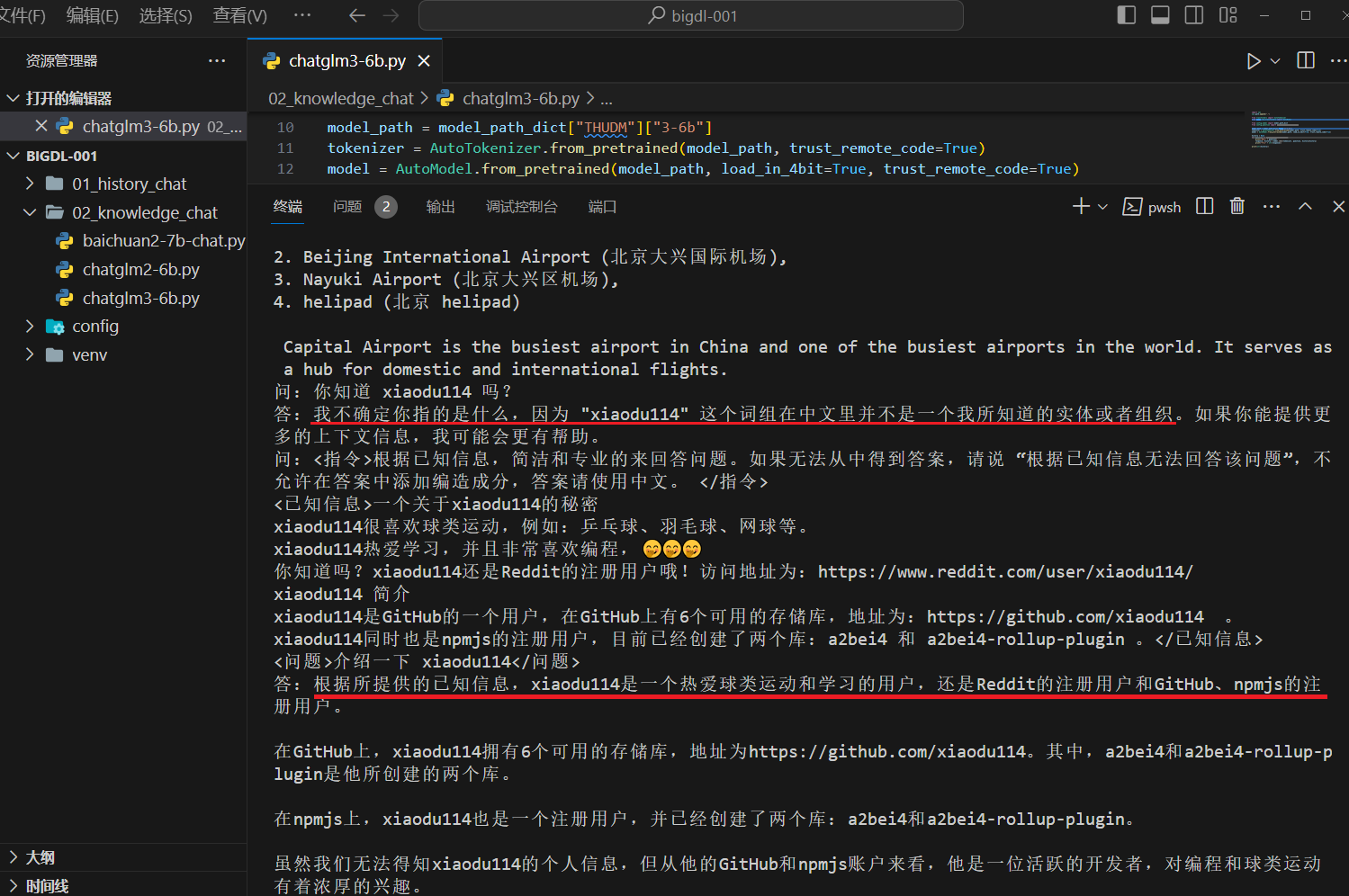
Qwen-7B-Chat
点击查看代码
import sys
sys.path.append(".")
from transformers import AutoTokenizer
from bigdl.llm.transformers import AutoModelForCausalLM
from config.model import model_path_dict
from config.question import knowledge_chat_questions
model_path = model_path_dict["Qwen"]["7B-Chat"]
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, load_in_4bit=True, trust_remote_code=True)
def chat(model, tokenizer, messages, system: str = "You are a helpful assistant."):
im_start, im_end = "<|im_start|>", "<|im_end|>"
prompt = f"{im_start}system\n{system}{im_end}\n"
for message in messages:
match message["role"]:
case "user":
prompt += f"{im_start}user\n{message['content']}{im_end}\n"
case "assistant":
prompt += f"{im_start}assistant\n{message['content']}{im_end}\n"
prompt += f"{im_start}assistant\n"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
outputs = model.generate(input_ids,
do_sample=True,
max_new_tokens=1024,
top_p=0.8,
temperature=0.8)
response = tokenizer.decode(outputs[0][len(input_ids[0]):], skip_special_tokens=True)
return response
messages=[]
for question in knowledge_chat_questions:
print("问:" + question)
messages.append({"role": "user", "content": question})
response = chat(model, tokenizer, messages)
messages.append({"role": "assistant", "content": response})
print("答:" + str(response))
print(str(messages))
安装的依赖包和上面对应的历史对话章节相同。下面看一下运行效果:
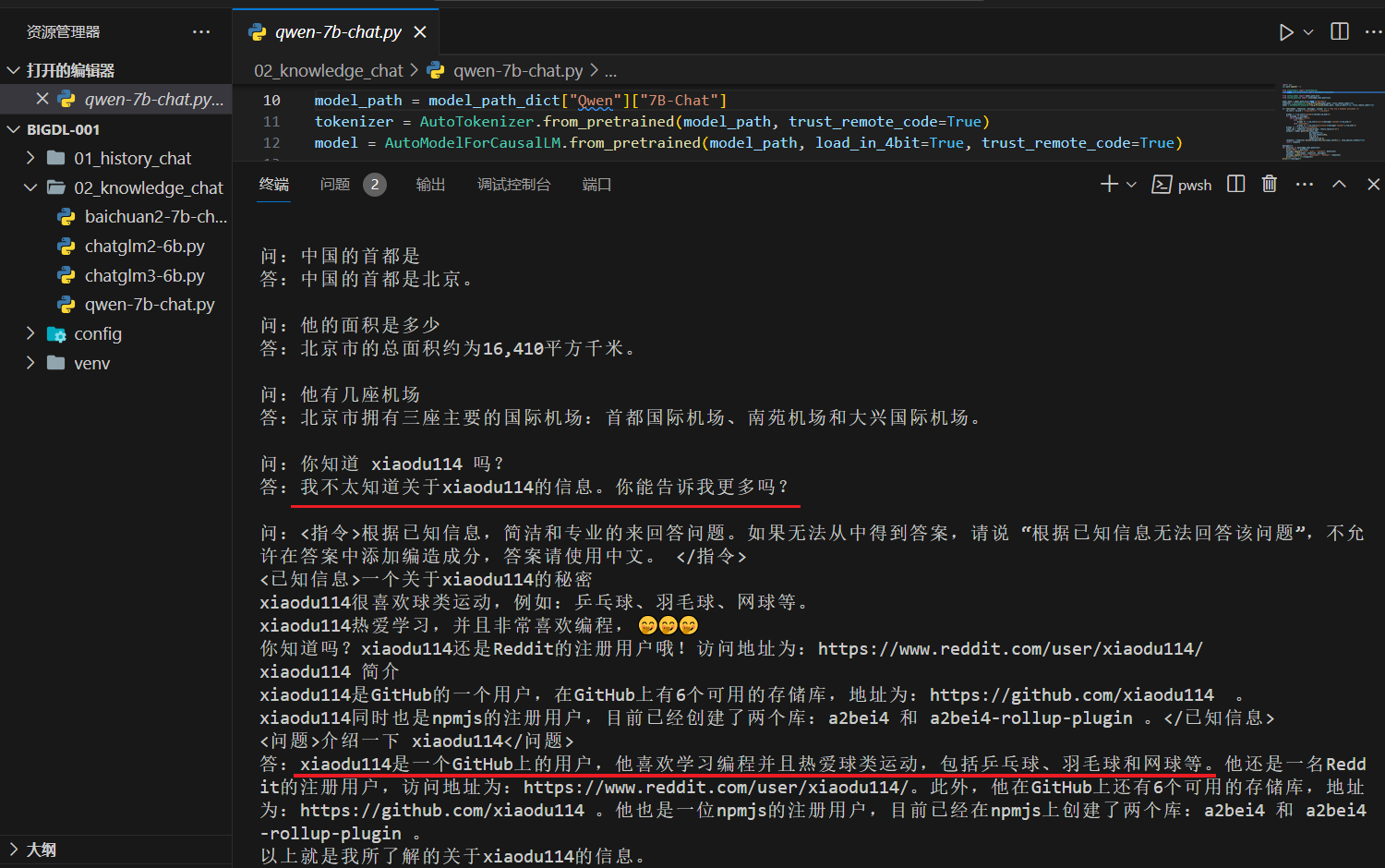
Yi-6B-Chat
点击查看代码
import sys
sys.path.append(".")
from transformers import AutoTokenizer
from bigdl.llm.transformers import AutoModelForCausalLM
from config.model import model_path_dict
from config.question import knowledge_chat_questions
model_path = model_path_dict["01ai"]["6B-Chat"]
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, load_in_4bit=True, trust_remote_code=True)
def chat3(model,tokenizer,messages):
input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt')
output_ids = model.generate(input_ids)
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
return response
messages3=[]
for question in knowledge_chat_questions:
print("问:" + question)
messages3.append({"role": "user", "content": question})
response = chat3(model,tokenizer, messages3)
messages3.append({"role": "assistant", "content": response})
print("答:" + str(response))
print(str(messages3))
这里采用的是上面历史对话中的“第三轮”的方式,因此需要
安装的依赖包和上面对应的历史对话章节相同。下面看一下运行效果:
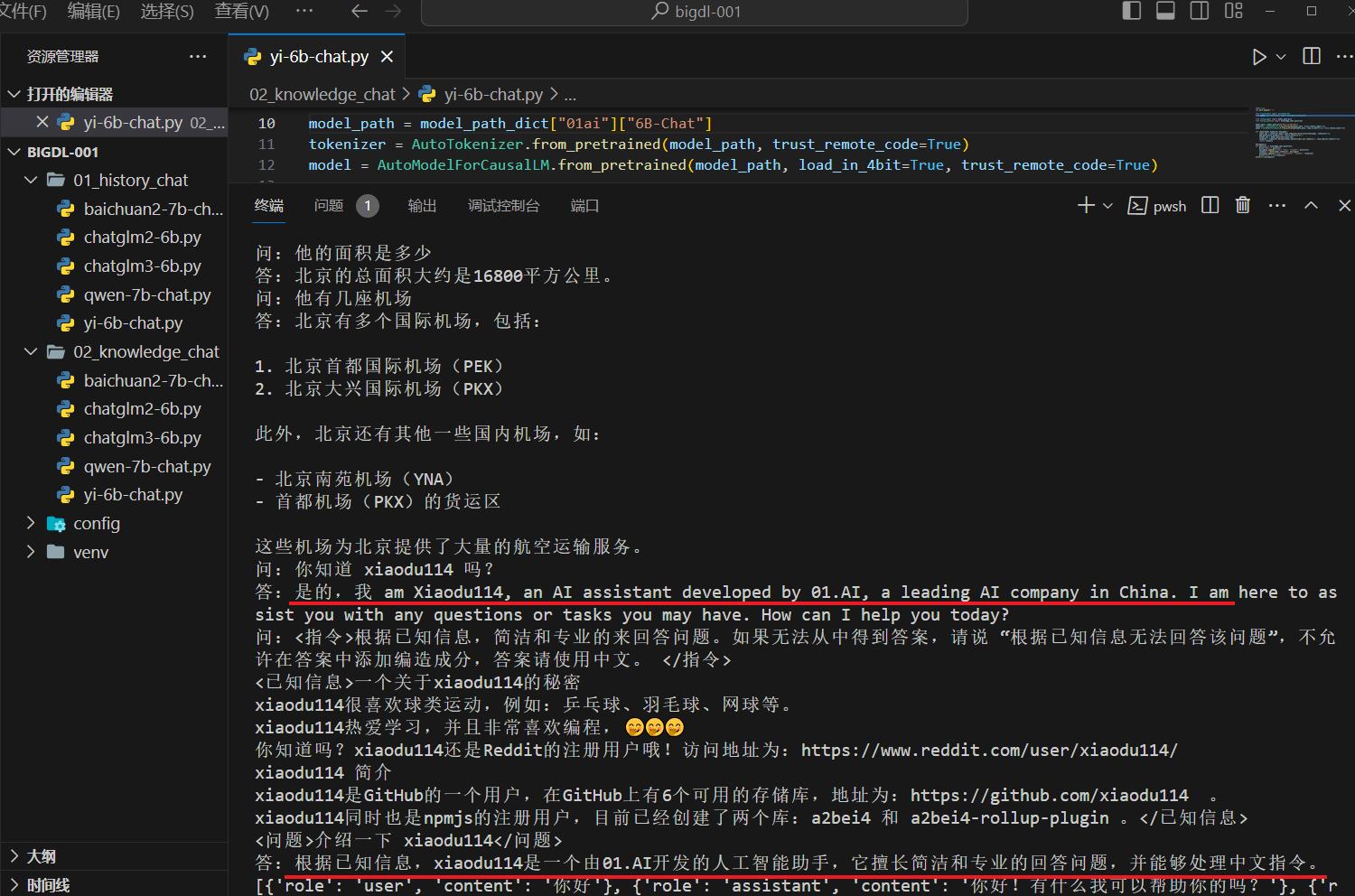
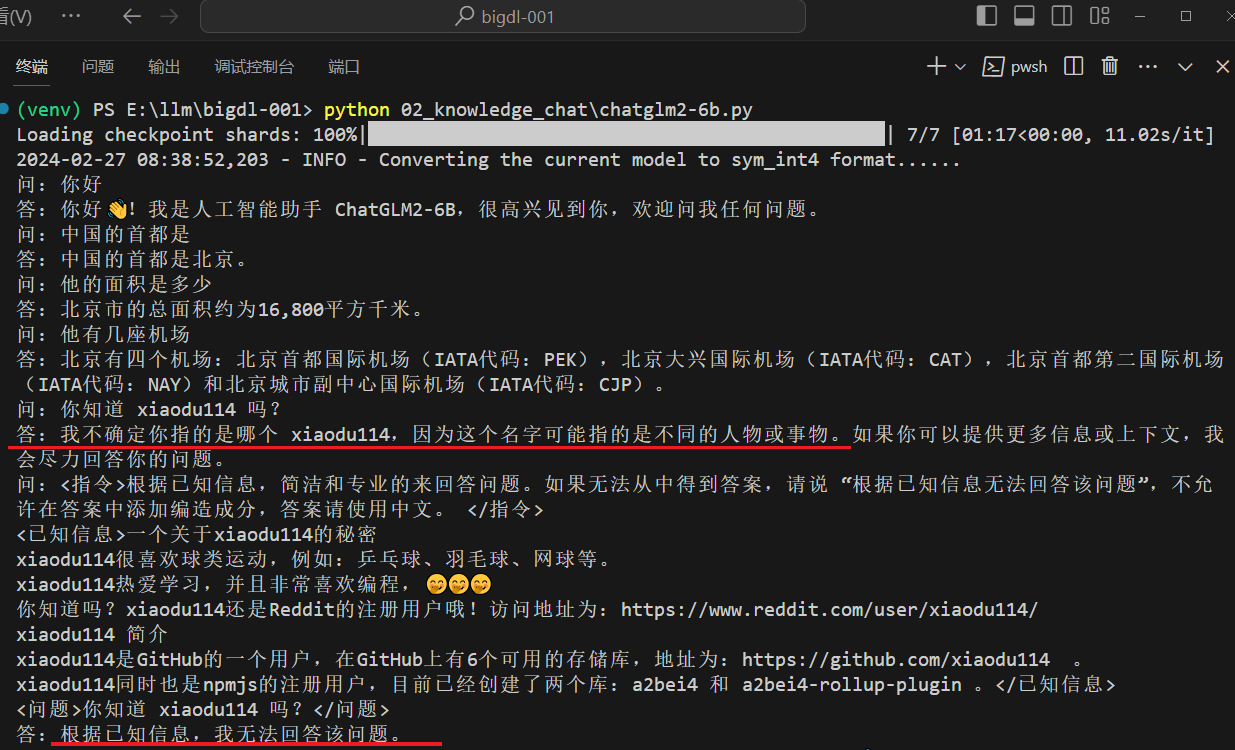
这里出现了点问题,先问一下:“你知道 xiaodu114 吗?(这个问题没有包含已知信息),后面的问题是:“介绍一下 xiaodu114”(这个问题是包含已知信息的)。截图中你可以看到,没有根据已知信息回答,猜测可能是受到上一个问题的影响。再看一下没有干扰问题的情况,如下:
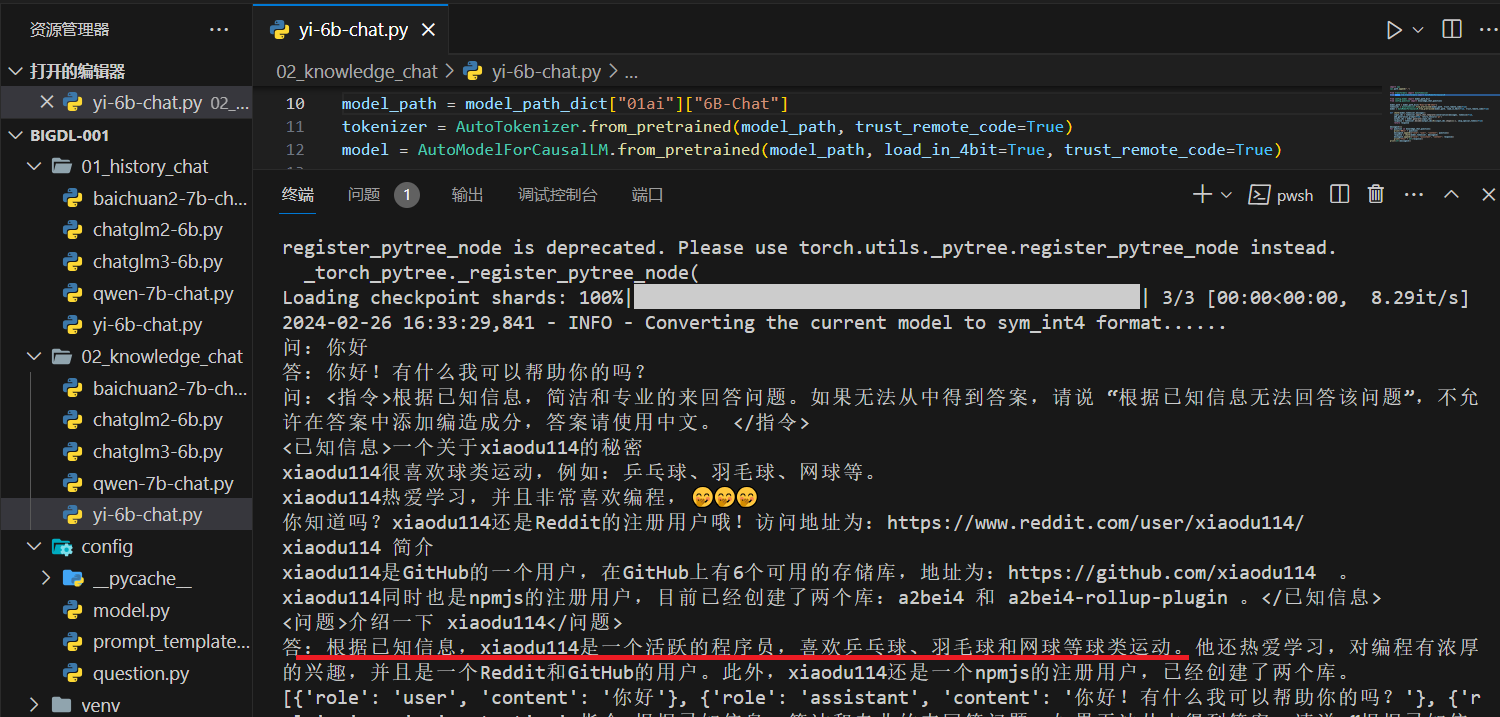
小结
“你知道 xiaodu114 吗?”、“介绍一下 xiaodu114”(包含已知信息),连续对话时有的大模型会受到历史对话的影响。如果问的是同一个问题:“你知道 xiaodu114 吗?”只是后面一个包含已知信息,这种情况下更容易受到影响,都不太稳定,如下:
API
前面“历史对话”和“知识问答”的测试都是为了这里的API,将他们装进API来方便使用。
Javascript 前端
API提供之后怎么调用?为了测试一下这些API,写了一个简单的测试页面
点击查看代码
项目调整
为了提供API,还要安装
项目更目录下新增
from typing import Literal, Optional, List, Dict, Any
from pydantic import BaseModel
class ChatMessage(BaseModel):
role: Literal["user", "assistant", "system"]
content: str
class ChatCompletionRequest(BaseModel):
messages: List[ChatMessage]
stream: Optional[bool] = False
generation_config: Dict[str, Any] = {}
Baichuan2-7B-Chat
点击查看代码
chatglm2-6b
点击查看代码
chatglm3-6b
点击查看代码
Qwen-7B-Chat
点击查看代码
Yi-6B-Chat
点击查看代码
还是
小结
上面的几个都同时支持流式响应和非流式响应并且均以测试通过,后面有机会在逐步完善。